繼前幾天靠著AI強大的編碼能力將ROみたいなカウンターHTML5化之後,緊接著在下又把念頭動到在這個部落格使用超過10年以上的Wordpress插件,MP-Ukagaka上了。事實上,在下在將PHP以及Wordpress的版本升級時,MP-Ukagaka就因為相容性出了一點問題,畢竟外掛的作者自2012年後已再無更新,可以在這個部落格撐這麼久,作者寫代碼的功力應該是相當了得吧…
回到正題,猶記10多年前在下剛設置這個外掛不久時,曾經提到過對於該插件會在網頁原始碼底部內嵌經過加密的台詞的設計不是很滿意…一直希望有朝一日能將它改成讀取外部文件如.txt的方式來輸出台詞…無奈在下對jQuery、JSON這類程式語言根本一竅不通,這個想法自然也就在歲月無情摧殘之下漸漸消失了(´ー`)y-~~
既然上次有了AI的幫忙讓在下嘗到了甜頭,得以徹底HTML5化了舊時代的ROみたいなカウンター,那麼再搞一次又何妨呢?是的,經過這兩天的廢寢忘食,AI果然沒讓我失望,在下終於實現了10多年前的怨念(遠目
<div id="ukagaka_msglist" style="display:none;" data-file="dialogs/'.$dialog_filename.'.'.$ext.'" data-load-external="true"""></div">就如上面mp-ukagaka.php當中的代碼所示,目前這個部落格所使用的MP-Ukagaka,已經從原本只能在網頁原始碼底部内嵌經過加密的台詞的模式,改造成為可以依照喜好,選擇讀取外部.txt或者.json的台詞檔案來運行了。當然,基於尊重原作者,内嵌台詞的模式依然予以保留。
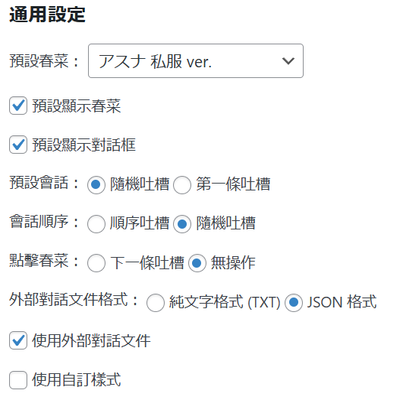
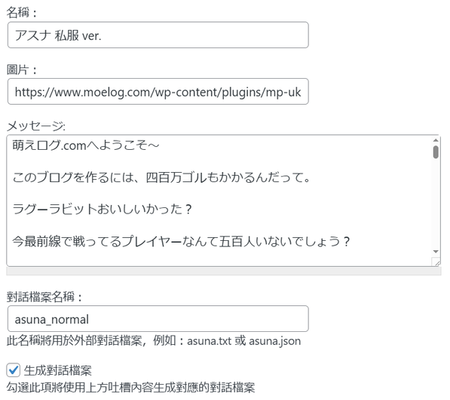
此外.txt或.json台詞檔案亦不用另外上傳,直接就可以在後台生成,且可以自訂台詞檔案的名稱。
當初在請AI修改成讓台詞以讀取外部檔案來運行的時候,因預設的春菜代號為default_1,所以讀取的.json台詞文件自然就被命名為default_1.json。這個還算可接受。然而新創建的春菜內建是用1.2.3的號碼來區別,亦即新創的第一位春菜,她的外部台詞文件會自動變成1.json,這種命名方式實在是太Low了,不符合在下的美學(?),所以在下就很執意的加入了這個功能w
另外諸如安全性的增強、代碼結構的優化以及用戶界面的改進等等,這個外掛要再戰個10年我想目前應該是沒有什麼問題了w
只不過美中不足的是,這個外掛仍存在著一個缺陷,那就是當台詞文件内容包含HTML標籤時,JSON在解析引號轉義時似乎會出現錯誤,不僅無法在台詞裡面正確的生成HTML語法,還會讓整個外掛無法順利運行…在下有一半以上的時間跟都AI在搞這個問題,無奈程式碼再如何修改,仍然無法解決這個問題,最終只好作罷…雖然對在下而言這並非是一定要有的功能,不過沒能還原作者當初的設計,倒是有些遺珠之憾就是了(´・ω・`)
2025/03/09:終於修好了,Claude想得太複雜了,這次是ChatGPT立了大功XD
2025/03/14:增加了自動說台詞的功能,約每5秒會自動更新一次。越來越像偽春菜了:D
但是話說回來,將MP-Ukagaka改成讀取外部檔案來運行之後,在下多少有點了解當初作者為何要用内嵌台詞的方式了,用外部讀取的話,感覺似乎增加伺服器不少負荷的樣子Orz
まあ、總而言之短期間內更新了3篇文章,下禮拜開始又要進入社畜模式了…ではでは。